

In this project, my group and I conducted research for comparison and recommendation between Systran and other available NMT engines in the market and selected the best option for a fictional scenario: assisting ANVISA, the Brazilian Health Regulatory Agency. ANVISA is an autonomous agency linked to the Ministry of Health and part of the Brazilian National Health System (SUS), acting as the coordinator of the Brazilian Health Regulatory System (SNVS) nationwide. According to the official government website, ANVISA’s role is to “promote the protection of the population’s health by executing sanitary control of the production, marketing, and use of products and services subject to health regulation, including related environments, processes, ingredients, and technologies, as well as control in ports, airports, and borders.” With this in mind, we focused on training a machine translation engine specifically for health-related materials, particularly vaccines.
Given the importance and scope of this subject, we aimed to ensure the NMT engine chosen for training and recommendation would present high levels of accuracy, precision, and integrity of technical information. We used Systran as our reference point for comparison, selecting Microsoft to highlight their differences, ultimately aiming to offer an informed recommendation to our client.
Given the importance and scope of this subject, we aimed to ensure the NMT engine chosen for training and recommendation would present high levels of accuracy, precision, and integrity of technical information. We used Systran as our reference point for comparison, selecting Microsoft to highlight their differences, ultimately aiming to offer an informed recommendation to our client.

What Were the Goals?
The engine would be considered viable if it meets the following criteria for post-edited machine translation.

Key Highlights of this Project:
1. Finding and extracting sufficient data
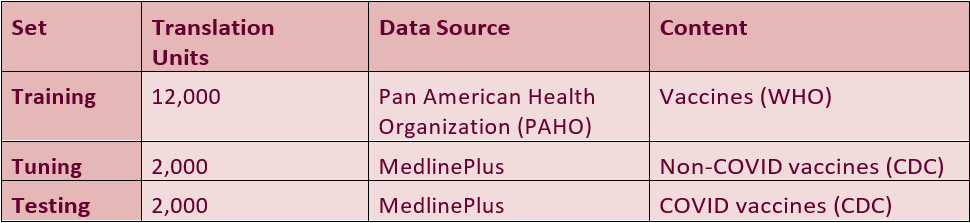
The initial step was to locate the necessary materials in both Brazilian Portuguese and English for engine training. Acquiring a substantial dataset posed the first challenge due to the considerable volume required, amounting to thousands of translation units rather than just individual words, and yet, under the permitted limit imposed by the engines. Initially, attempts were made to utilize materials from HealthLine Plus, but they proved insufficient. The Pan American Health Organization, on the other hand, provided an extensive library of Portuguese files with corresponding English translations, significantly increasing the number of translation units. To overcome limitations in the number of characters permitted and achieve the desired dataset size of 10,000 translation units, a shift in strategy was implemented, transitioning from sentence-based segmentation to phrase-based segmentation. That change allowed us to achieve the sufficient number of translation units.
2. Quality Metrics and File Preparation
For this project, we adopted the Multidimensional Metrics Quality framework to tailor our metrics specifically to medical translation evaluation, focusing on error types such as medical terminology and compliance. Right at the early stages, however, we discovered that Systran did not support docx files. That forced us to resort to less efficient methods, such as converting pdf files for manual alignment, which proved time-consuming due to the complex formatting of materials, including graphics, image descriptions, and text-heavy headers and footers commonly found in newsletters. Despite the setbacks we were still fortunate to have chosen some efficient tools for part of the work like AutoAlign, WordFast, and Olifant. Manually aligning approximately 20 files became a challenging and slow part of our experiment, highlighting areas for improvement. Suggestions for future experiments include utilizing existing TMX files generated from previous translations using CAT tools and prioritizing automated processes like data cleaning over manual tasks such as manual alignment.
3. Establishing and Selecting the Optimal Engine: Systran vs. Microsoft
Configuring both Systran and Microsoft Training Engines involved a trial-and-error approach, beginning with considerations of file formats and character limitations. Throughout this process, we observed that Microsoft offered a more user-friendly interface, which facilitated manipulation and comprehension. To narrow down factors that would help us compare and chose only one of them, we ran our first round of training in order to generate translations that could be used for subsequent post-editing (PEMT) evaluation based on the following criterion:

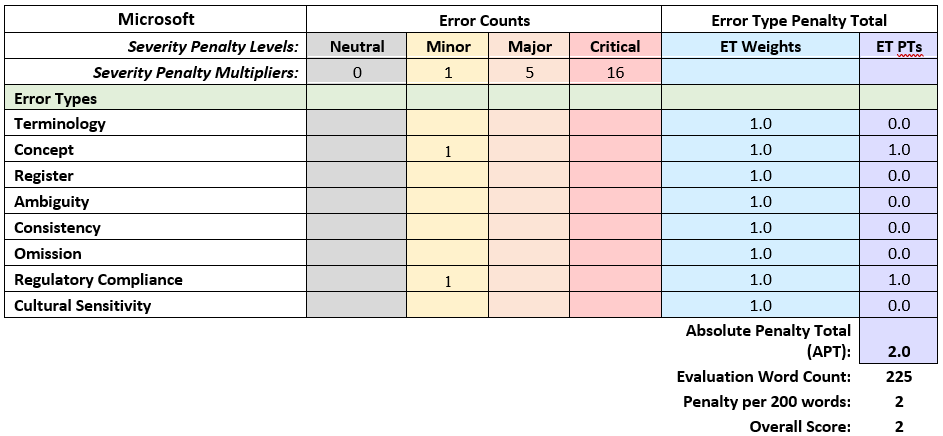
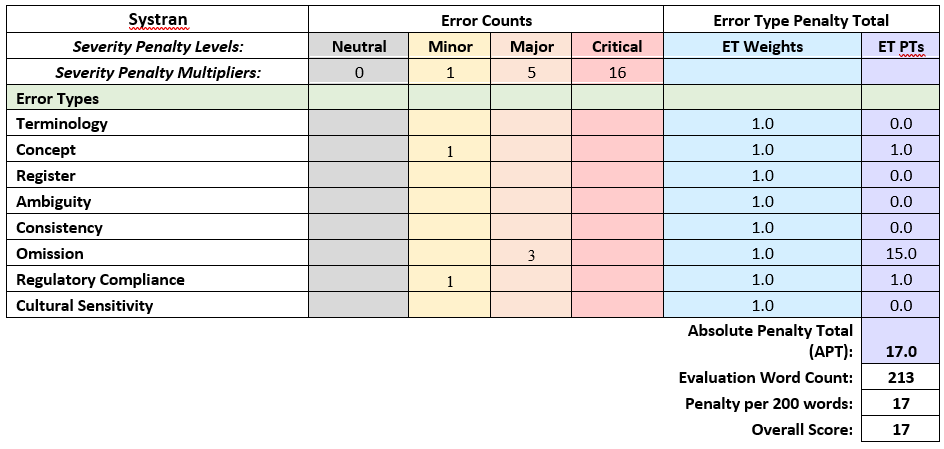
Following the initial training phase, a human evaluation was then conducted on a small sample of approximately 200 words. As the native speaker member of our group and also an experienced linguist, this task was a welcome task . This assessment aimed to point us to which engine provided superior translations, with fewer critical problems.
4. Training Process and Rounds
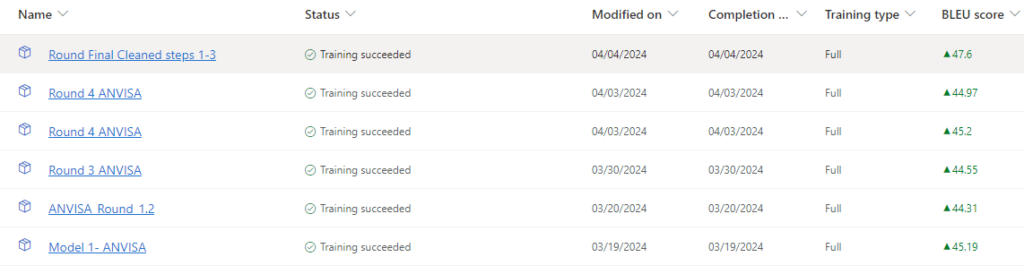
After post editing evaluation results, our choice to Microsoft as our engine became resolute. We proceeded with the remaining nine rounds of training. Each time, we carefully allocated the most appropriate datasets into the training, testing, and tuning sections of the engine. While we recognized that BLUE scores do not provide a definitive measure of quality, we did note improvements in each successive round.
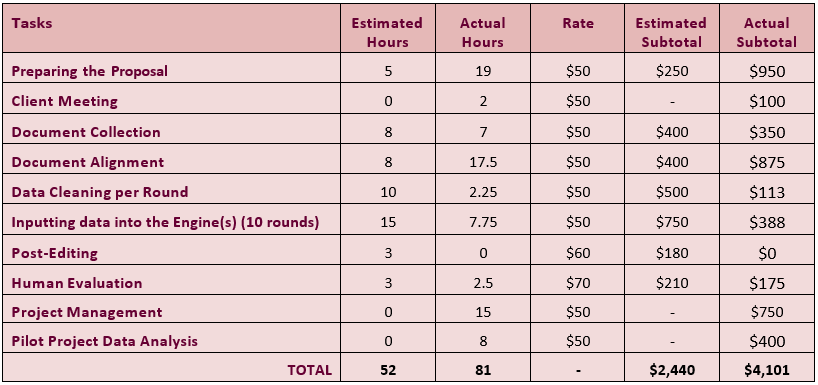
5. ESTIMATED AND ACTUAL COSTS ANALYSIS
Following the completion of our experiment, we drew significant conclusions regarding the disparities between estimated and actual costs. This was especially evident when considering factors such estimated and actual work hours and project planning.
6. CONCLUSION AND FINAL RECOMENDATION
CHOSEN ENGINE: MICROSOFT

- Less document format requirements including naming conventions
- You can autoalign in the engine via parallel function
- It has a more user-friendly interface and clear indicators for data as well as individual workspaces for teams
- Generated less penalties based on the metrics used and yielded higher BLEU scores
- No critical or major errors while Systran had 3 major errors